Special Theme
An Approach of the Info-Forum Museum
Database as Collaborative Environment
Why, when museums consider collaboration over their collections, does the database inevitably come up as a pivotal player? I have been involved in museum databases, all collaborative in some sense of that word, for over 40 years, yet I still find this question hard to answer. In one sense, I can answer the question easily. Databases always come to the table, early, because they are both the information technology of collecting institutions and because digitality has been, for many years, endowed with the apparent qualities of exactitude, access and authority, qualities that are seen as essential to guaranteeing access to authorised expertise. However, I also find it difficult to offer a meaningful explanation as I know that digitality, and databases in particular, offer none of these qualities to information, necessarily. In fact, the only generalizable qualities of digitality, whether databased or not, are diverse multiplicity and local performativity (Boast 2017). So how do we approach this problem of databases and collaboration? What does digitality bring to the table that is unique and essential, if anything?
I was going to approach this problem, the problem of digitality, of databases and collaboration, from the point of view of the genealogy of representation in anthropological museums. The reason I wanted to start there was that so much of what we see as ”documentation,” the information about collected objects, is constrained by a set of historical conditions that establish the entitlements of what can, and cannot, be done and said. In Philosophy we call these entitlements ontology. We are not going to go into the complexities of philosophical metaphysics here, you are, I am sure, glad to hear, but the understanding of what my colleague, Esther Weltevrede, calls “affordances” (Weltevrede 2016: 10-14), that these cultural traditions impose, are central to our concerns here. The affordances are not just found within the culture of the institution, as I was going to discuss, but also in the culture and cultural histories of the technologies we seek to apply.
However, the more I wrote this article from this point of view, from the institutional point of view, the more distant digitality became. So I decided that it was better to approach the problem from the side of digitality. We will get to the museum at several points, but I think from this direction, that of the digital, my points will be better made. Mostly because I want you to come to consider digitality a very different thing than you may be used to.
We have all contributed to this special theme because we believe that it is possible to break with tradition, western museological tradition, and create a collaborative understanding of the objects held within anthropology museums. An understanding, or set of accounts, that are co-created by both the museum and the communities whose patrimony these objects are. However we often also believe, without breaking with western tradition, that digitality and databases somehow, by their technological personalities – their innate affordances – are best suited to achieving these goals. My goal here is to fundamentally undermine this second assumption, of the inherent aptitude of technology, but ultimately support the first assumption, that we can co-create meaningful accounts of the shared objects collected in museums. But first we must dispel a number of beliefs that we sustain about what digitality is, and what databases are.
I would like to begin my alternative exploration of digitality by quoting Brian Cantwell Smith from the first paragraph of his entry for the Catalogue of the exhibit N01SE: Universal Language, Pattern Recognition, Data Synaesthetics held in Cambridge UK in 2000 (Lowe and Schaffer 2000). Here Cantwell Smith neatly summarises the problem I wish to address today. Both asking the question, What is digitality?, but mostly, Why do we think it is something epistemologically pure? As he says: “It seems as if Plato's heaven is being replaced by the eternal perfection of an abstract realm of 0s and 1s.” (Cantwell Smith 2000) My goal here today is that we should all wind up with an understanding of digitality far messier and noisier that we started with, and far far noisier and messier than this general assumption.
I wish to approach these questions genealogically, through several brief, provocative histories. And, in my first history, I wish to start by attacking one of the more fundamental beliefs about digitality, one repeated here by Cantwell Smith. That digitality is about 0s and 1s.
There are only 10 types of people in the world: those who understand binary and those who don't.
For those of you who get this very geeky joke, we could reword it by saying that practically no one understands what digitality is, though there are people who do understand what binary is. One thing that digitality certainly is not is 0s and 1s. The almost universal representation of digital code, as 1s and 0s, is in fact a mere metaphor. 1s and 0s are stored digitally, but as capacities that signal an on or an off, not as 1s and 0s. Something much messier and more interesting is being created when we create digital signals. Something whose implications will, I hope, draw our attention towards future solutions.

Figure 1. Émile Baudot's Digital Telegraph from 1974 (Lower Right), with a Sample of Baudot 5-bit Digital Paper Tape (Behind).
To find some clarity here, we need to go back, way back. Figure 1 is an image of the very first digital media, the first instrument that was fully digital. It is not a computer, nor does it calculate. It is an information storage and transfer device – it is a telegraph.
The figure is of the telegraph of Jean-Maurice-Émile Baudot, a French telegraph operator who invented this device to overcome the problems of transmitting a high volume of telegraphs via Morse’s Code. This telegraph overcame many the problems by simply transmitting letters not as a complex interpreted five-level code, which Morse’s code is, but as a much simpler code, a digital code – ons and offs. Using a 5-bit encoding, Baudot’s telegraph offered accurate message transmission, multiplexed for high volume, by 1874.
Baudot’s telegraph would be simply a mere bit of historical trivia if it were not for the fact that his digital encoding not only became the exclusive form of telegraph transmission by the beginning of the 20th century (yes, all telegraph transmissions were digital after 1918), but also because his 5-bit encoding of the capital Latin letters are the same encodings that our computers use today.1
In Figure 1 we see that Baudot's telegraph was not simply about transmission, but also about storage. Key here is his paper tape (shown behind the telegraph image) which does not encode by 1s and 0s, but by holes and not-holes. The not-holes are as important as the holes. Passing through the electrical reader, this produced an encoding of synchronous ons and offs. It is the encoding of synchronous ons and offs that characterise the digital, not binary numbers. This is the pattern of the digital. It is not binary, it is not numbers, it is not mathematical. It is merely the simplest of presences and absences. A synchronous series of something there, or something not there – synchronously, electronically, on, off, off, on.
This simplicity is critical to understanding the digital. The simplicity of digital encoding is not only foundational to its entire genealogy, but it is also critical to understanding the medium that we work with today. Because the digital is not numbers, it is not ontologically numeric. It is not ontologically mathematical. It is not ontologically computational. Computers are not called computers because they compute, … but that is a different story (Grier 2005).
What digital encoding necessitates is transfiguration – a processing into something. Processes must exist for digital encoding to be anything – anything other than a series of ons and offs, and what these processes can produce are limited only by our expressive desires. Yes, you read this correctly, our desires to express something, anything. Digitality is an expressive media, not a computational technology – though our desires might extend into expressing mathematics as well.

Figure 2. MIT's 1949 Whirwind Computer Console with the First Interactive Device (the Light Pen) and the First Computer Graphic. (Photograph is used and reprinted with permission of The MITRE Corporation. ©2016. All other rights reserved.)
To make my case of the genealogy of this technology being a history of expressive desire, we don’t have to go back again as far as the 19th century (though telegraphs are nothing if they are not expressions of desire), but we can go back to the callow age of electronic computers. Figure 2 is a photograph of one of the first fully digital computers. Well, actually, the computer is off the screen as it was the size of a small house, but we do have the first computer interactive device (the light pen), and the first computer graphic (the “MIT” made up of dots). All of these three devices were brought into being within months of each other, on the same site in Cambridge Massachusetts, in the winter of 1948-1949 (Redman and Smith 1980).
This now familiar use of an electronic computer, as an expressive medium through text, image, graphics and sound, did not simply arise from the creation of the first fully digital computer, the Whirlwind Computer of MIT’s Lincoln Lab, but emerged through its genesis. The digital as interactive, expressive media was immediately realized as a quality of digital encoding. The new Computer, with digitally encoded information processed via Claude Shannon’s logic relays, was to transform what was originally intended to be a fast computer – a machine that calculated what people calculated, but faster – into an expressive media, one that you could interact with.
Throughout the 1950s, a period we are told was dominated by calculation, in fact electronic computers were largely dedicated to the graphical expression of and interaction with encoded information. On the successor to the Whirlwind computer, the TX-2, Ivan Sutherland, a student of Claude Shannon, had built by 1959 the first object oriented interactive graphic system: Sketchpad. Even the first use of digital computers by the US military (SAGE) was an interactive, graphical system that transformed vast quantities of distributed data into mediated expressions, albeit of airborne nuclear threats, such as ballistic missiles. Verisimilitude was never the goal, and by 1960 computers were almost wholly dedicated to expressive mediation of information and data, and users' creation and interaction with it (Boast 2017:133-147).

Figure 3. Very Poor Screen Shot of the Xerox Alto Computer, at Xerox PARC, during their 1979 Demo for Apple Computers. https://www.youtube.com/watch?v=dXgLY0PRJuw
It is important to remember that the fully developed digital media environment that we are familiar with today, on all of our devices, was largely imagined by 1965 (Nelson 1965), and working, in some form, by 1974 (Kay 1975). The interactive digital media that we think of today as a development of the internet, was imagined and assembled by the mid-1970s. In Figure 3 we see a bit of a demonstration of the Xerox Alto computer with a mouse and keyboard, bit-mapped graphics, local area networks, folders, files, menus, editable text, interactive databases, digital video, and a host of other features familiar to us today. Though the Alto system was operational by 1975, this demo was given in 1979 by the team at Xerox PARC to a team from a new and upcoming company in the area lead by a very young Steve Jobs. This is where Steve Jobs first encountered the full expressive potential of digital media, and went off to develop the Macintosh.
At the time that the computer was developing its potential as a media device, so ideas about how we store and organise the information held digitally was also being developed. Though data had been stored on computers since the early 1950s, it generally was compiled and formatted for specific ends. This was to change from the early 1960s as very large governmental and military projects required vast quantities of searchable, reusable information. One of the first was IDS (Integrated Data Store) developed by General Electric in the early 1960s.

Figure 4. Original "One Million Pigeon Holes" Diagram from Charles Bachman's 1962 IDS report for GE.
IDS was the first time that someone thought about what a digital database might actually do – what advantages non-specific digital information might have. It was virgin territory. Figure 4 is of one of the illustrations for the first design brief for IDS from Charles Bachman and his engineers (Bachman 1962). We see them thinking with the metaphor of the pigeon hole, but a million of them. Of course today we think in billions or trillions of records, not merely millions, but for the GE engineers in 1962, this offered mind-blowing possibilities.
One of the first realisations of the GE team was that unlike a large bank of pigeon holes, or a room of card catalogues, the digital database could be cross referenced in as many ways as you wished. There was literally no limit, but for the time of the programmers, to what structures and relationships could be built with digital databases. As the GE engineers stated in the report: “A record may be cross referenced as many times as necessary!” (Bachman 1962, Figure 8). Digital databases were places where data could, for the first time, practically be related in any way you wished.
The ideas in IDS would be later picked up by IBM for the development of its IMS (Information Management System) which it developed with Rockwell and Caterpillar, starting in 1966, for the NASA Apollo program. IMS was the first widely used database management system, rather than a structured storage system, and formed the only database platform IBM would offer until the 1980s.
In the callow age of the database, in the 1960s, there was little in the way of constraints. The database was seen not as a system or a platform, but as a layer. More like a library than a museum – much like our current file-systems – the database was seen as a structured collection of information objects that could be accessed by a diversity of users and systems, as needed, in whatever form the immediate process required. There was little in the way of fixed structures, except ad hoc ones, and databases were build much as today we build apps. As the need arose.

Figure 5. Grace Hopper and her COBAL Team Working on ENIAC in the Mid-1960s.
Databases and digital media had a profound effect on not only how people interacted with the new electronic computers, but also how they were built and assembled. In Figure 5 we have Grace Hopper, who also created the first compiler, and her team of programmers working on ENIAC in the mid-1960s developing COBAL, one of the earliest high level programming languages. Computers themselves were developing as highly configurable media machines. The levels of loose data storage and configuration, multiple levels of processing, afforded by a highly transmutable digital encoding, allowed for hugely creative leaps in how computers processed information. However, this was all about to change.
Edgar Frank, better known as 'Ted,' Codd, was a computer engineer who worked for IBM from the late 1950s to the late 1970s. Ted Codd was an Englishman who had moved to the US in the early 1950s. Working at IBM in the 1960s, mostly on technical aspects of IMS, Codd was struck by how the “database experts” he was working with had no knowledge of mathematical logic – what is called first-order predicate logic. Now, you may think that this obscure opinion of an obscure IBM engineer is rather unimportant, and it may have been, but that Codd wasn’t going to leave it at that. From the end of the 1960s, Codd began working on a model for what he thought databases should be. They should be efficient, and searches should be based on predicate logic, not ad hoc, local needs. Databases should be rational.
What Ted Codd did, by 1974, was to devise not only the conceptual structure of such a database, but largely work out how it should be built. It was based on data tables (those things we use to learn about in school where the rows were records, and the columns were characteristics), and the tables were related to each other by key fields. The relational database was not a collection of information that would be accessed by a program only, but it was a structure – a structure that arose from the information itself, allegedly, rather than from its use. These relational structures, now so common, may be familiar to some. But even if not familiar, it is indicative of what we usually now think of as databases. We should, however, unpack this a bit.
The relational database of Ted Codd is not one unified entity, but an assemblage of entities. Comprising the database are a number of tables. Each table should, according to Codd’s database theory, relate to a coherent entity. Not an object, but a coherent aspect of the objects which will be recorded in the table. For museums, a table may be about the accessioning event, it may refer to the exhibition history of objects, or the conservation history. There really should be a table about the description of the object itself. Tables should also contain incidental information such as term lists and names of collectors or researchers. Tables are comprised by records, each which does refer to an object or an event (or a person). The objects recorded in the records are represented by fields or discrete bits of data, still coherent, that consistently describe categorically the object or event within the context of the table.
This can get very complicated. As relational databases are not only hierarchical assemblages, but they are also relational networks, the key to a "proper" database for Codd was that, in all this structure, nothing should be repeated – each entity, and its characteristics, should exist only once. All information should be recorded just once and then related to other tables of unique information via complex predicate logic. The whole point, the epistemological necessity, of a Relational Database is that it breaks the database referent up into discrete bits that both wind up representing the entirety of the referent, but do so by not overlapping – with no redundancy. In database theory, this is called Normalization. Each table is then related to other tables by shared keys composing a model, or ontology, of the referent, for example the operations of a museum.
When Ted Codd proposed his new Relational Database Model to IBM, in the early 1970s, no one thought it was a very good idea. Not least as there were other perfectly good proven database models about, for instance IBM’s own IMS which it had a huge captive market for. However, by the 1980s, the world of computing had changed substantially. As I had discussed before, the world of personal computing environments had been largely developed by the mid-1970s, and by the early 1980s, Apple, DEC, IBM, Compaq, Acorn, BBC and a slew of new companies were filling the market almost ubiquitously with personal computers. With the associated need for generalized database systems, mostly for small businesses, did the Relational DataBase Management System (RDBMS) model gain prominence – basically by the late 1980s.
Throughout the 1990s, relational databases became so prominent that even the definitive Manga Guide to Databases (Takahashi and Azuma 2009) only dealt with relational databases. Relational databases dominated not only business and academic markets, but their ease of use and increasing speed would become the information back-end of the exploding Internet. However, despite its domination, backed by the authority of Manga, the limitations of the relational model quickly became apparent.
The seeds of the demise for such a rational and highly structured approach to information management were sown with the rise of the World Wide Web. With the explosion of unstructured and semi-structured information, the highly distributed data infrastructures that now dominate online information systems, such as the cloud, as well as the diversity of contexts in which information now must be accessed and used, contexts of use that now dominate all of our online lives, the relational database, with its demands for strict structure and representation, could not accommodate. For much of the early 21st century, we have seen an explosion of completely new databases, based on non-relational, novel models for organizing, finding and managing digital information – usually vast quantities of it.
In 2009, Johan Oskarsson, a programmer at a company called Last.fm, organised a conference in California to explore the many new "open source distributed, non-relational databases" (NoSQL 2009). Google's BigTable/MapReduce and Amazon's Dynamo are the best known, but there are dozens of open source clones and alternative models. Oskarsson’s event needed a Twitter hash-tag, as we do today, and he decided to use the hash-tag #nosql, SQL being the Structured Query Language of the relational databases. Hence a name was given to a movement already well underway – NoSQL (Strauch 2011; Redmond and Wilson 2012).
The models for the new databases are often radically different than Codd’s model. Relational databases were structured, relational only in the sense of predicate logic, rigidly consistent, and stable to the point of inflexibility, but the online world was seeking ways of working with distributed, diverse, unstructured and even incommensurable digital information that needed to be far more flexible, emergent and unstable. More so, today's information culture needs, even demands, access to information based on local needs and ad-hoc approaches. Basically, a return to the 1960s – at least in principle.
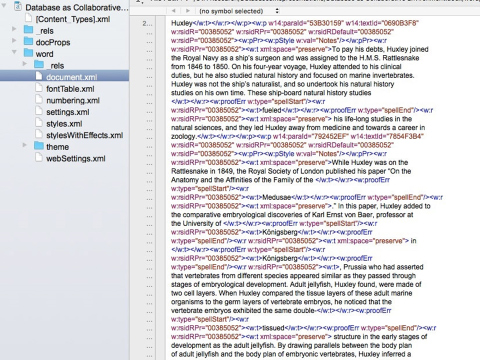
Figure 6. Example of a Word File (Microsoft® Word for Mac 2011), Showing the Assemblage of Files All Stored as Data in XML.
As an example, let us think of a different way of storing data, a much older way. When we create our documents, we are not creating a single file, typed as we see it on the screen, but an assemblage of files with vast quantities of information embedded within them. Figure 6 shows a small bit of my Word document of notes for a class. Not only is my document made up of no less than 20 different files, but the content of the files is dynamically semi-structured. This is true for all digital files today. They contain vast quantities of information, marked-up and documented in the documents themselves. What if we, instead of classifying and recording our descriptions of these documents in a database, just store the documents themselves with a schema of how they are marked up and documented? What we could then do is to have a system, or many different systems, that allowed us to query directly the content of the documents themselves, even as they change. We may not consider this a database at all. However, a lot of people do just that today. In fact, the most common database today is what we call a document database.
Codd imagined a perfectly structured, logical world where all data clearly represented some aspect of an authoritatively defined object. Further, these representations could be logically related to other aspects of these objects in a stable and rigid way. However, we actually live in a very different world. A world of complex documents, dynamically changing and expanding, with arbitrary data-formats which change constantly. Documents that contain their own documentation – documentation that is recorded variably, because of very different, often incommensurable, contexts of production and use across multiple knowledge communities.
This is, of course, just one example. What we see today is a huge growth in different ways of working with information. Information that is enormously diverse and whose documentations of context are increasingly part of the document itself. It is as though we have returned to the early, callow days of databasing. Days where the use and purpose of the information held precedence over rationales, over models of knowledge. These hybrid information objects are not the only thing that is driving the diversity of what we call databases and information management. The enormous diversity of what we do with information is also driving a diversity of ways of managing, finding and reusing information.
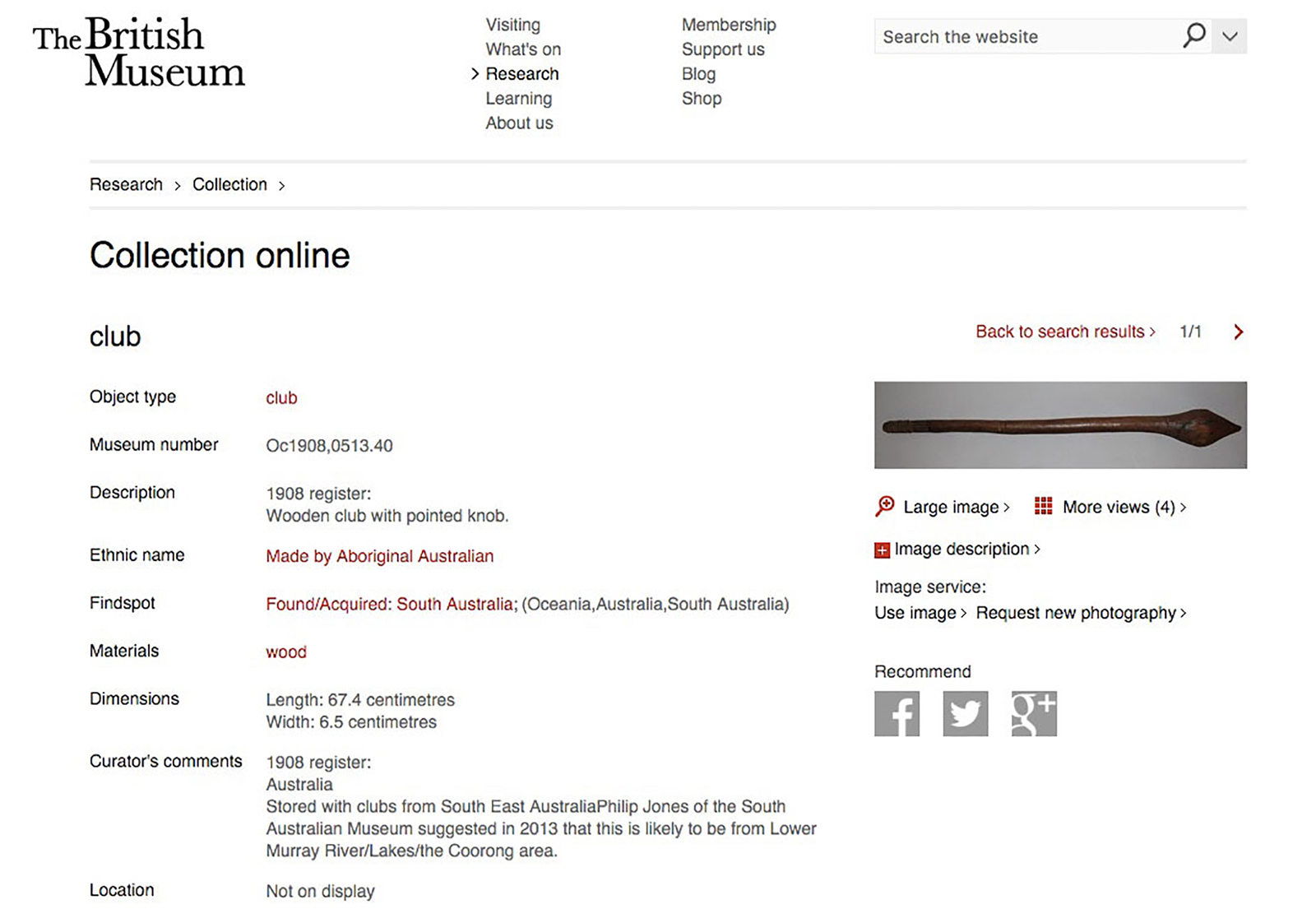
Figure 7. Search Result of "South Australia Coorong" in the British Museum's Online Catalogue. (Retrieved 17th of January 2016)
So what does all of this have to do with museums? We had to get around to the digital museum at some point. If it is not already obvious to you, then here is a brief example that may help. Figure 7 shows a search on the BM collections catalogue (http://www.britishmuseum.org/research/publications/online_research_catalogues.aspx). It is a search that I did, as I have done so many times over the years, to try and find the collections that I know the BM holds of a culture, the Ngarrindjeri of South Australia. The catalogue does not hold this culture’s name, but they do hold a club that is Ngarrindjeri. We know this because it is from the Coorong, of the lands of the Ngarrindjeri. However, this knowledge is not found in the database of the BM, but emerges from my knowledgeable use of the BM Catalogue and my knowledge of the Coorong that has been shared with me from the Ngarrindjeri who live there.
We find ourselves in this museum-enforced bind whenever we confront a system that has grown from the relational model – the strict logic of representation. We try to commensurate our search, our local desires and needs, to the rigors of the catalogue renderings, largely devoid of the rich cultural knowledge of other knowledge communities. When we have tried to rectify the dissonance that is always there, we keep trying to restore the grid, the rigid representational grid of tables, records, categories and prescribed relationships. Projects such as the RRN (Rowley 2013; Niel-Binion 2015), Kim Christen Withey’s Mukurtu CMS (Christen 2006), even Jim Enote’s, Ramesh Srinivasan’s and my Collaborative Catalogs (Srinivasan, Enote, Becvar, and Boast 2009) have all sought to commensurate such noise, such inevitable cultural dissonance, by merely applying relational databasing as though it would purify simply by its application.
As the catalogue before it, the database has become a fetishized schema in museums. It remains the most cherished of our technological mediations of our collected objects. Yet, we also understand so very little about it. My BM Catalogue search is the usual engagement we have with such a database, at least online, at least with collections. It is so pervasive that we assume that this is a stable and predestined schema. However, like digitality, so much of databasing is more fantasy than fact.
First, what we see when we look at the workings of the BM Catalogue is not simply a database, but the rendering of data as a catalogue. The data used is stored in a database, the Merlin database, a relational database, and the two are linked, but not deterministically so. Someone decided to describe these objects with this data. Someone decided to configure this data in a catalogue format. Someone decided to store this data in a relational database according to a relational model. Someone decided to not allow any other data or digital objects to represent these objects. None of these decisions were a necessity, they were all choices – desires manifest. It could have been otherwise, radically otherwise.
Hence we must come back to the digital. This series of ons and offs. It is essential to understand that this is our data, not the representations that we assemble on our webpages and in our repositories. This sounds an almost absurd claim, but I wish to push it even further. The point of the digital is that there is no necessary representational relationship between the digital code and the renderings we construct on the screen. None at all. This code represents nothing at all. The representation, the rendering, the performance is not in the code, but happens after we do something with this code. What we build is something we fashion, from raw materials, and what we can build is limited only by our desires to express – and the technologies we use to manifest them.
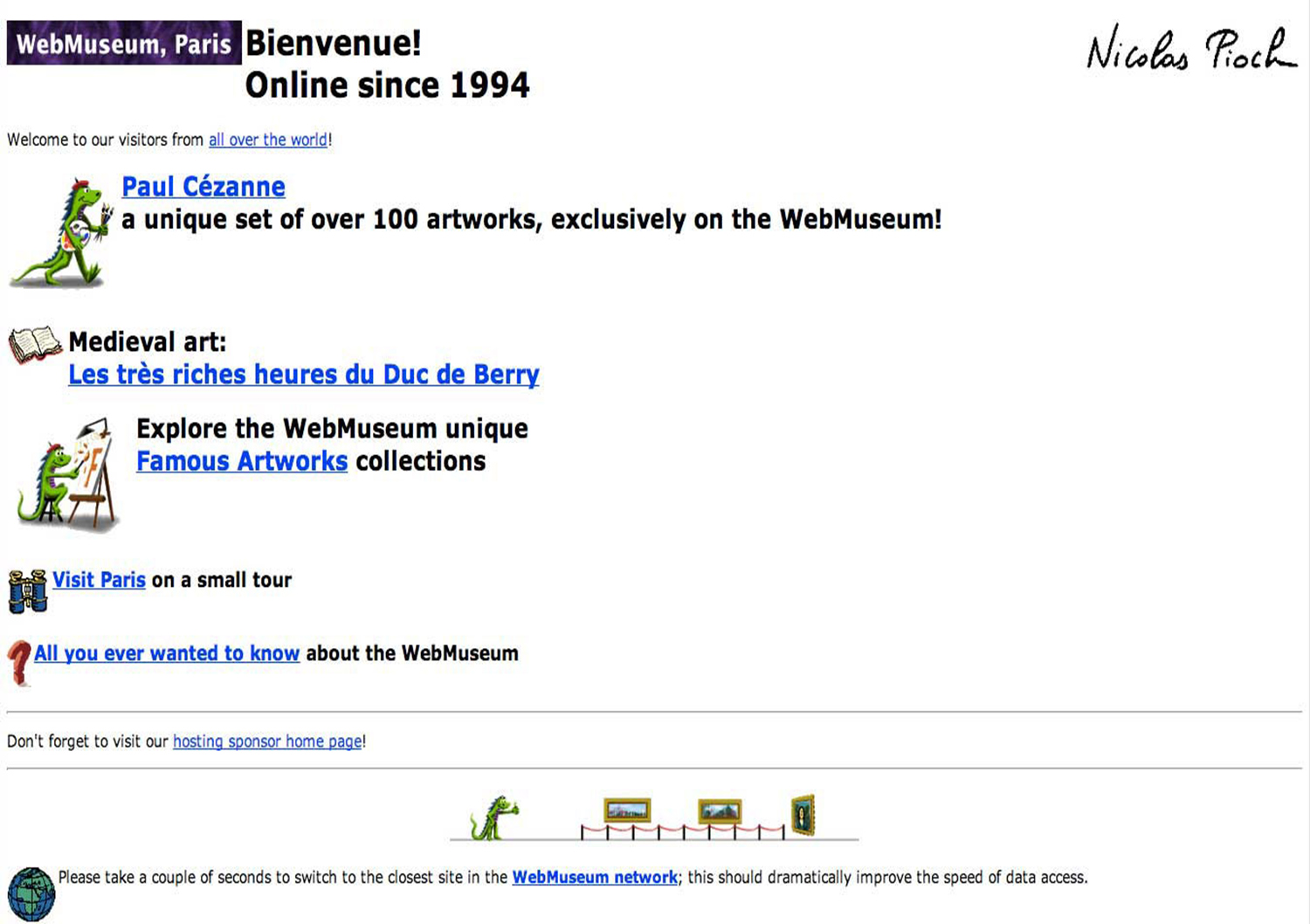
Figure 8. A Screen Shot of Nicolas Pioch's Original Home Page (1994) of the WebMuseum, Paris.
I do not need to just state this claim, but I can show it – or, rather, I can make you hear it. Figure 8 is an image of the very first museum web page. It was the project of Nicolas Pioch of Paris. He began building it in 1994 when the Web was less than a year old, and it is still online (https://www.ibiblio.org/wm/). If you download a “.jpeg” of this page, you can use a screen capture. You will now have an image file of the webpage, another form of its performance. Now you chose the filename on your desktop and change the file extension from “.jpeg” (or “.jpg”), to “.mp3” (Sound. 1). Now open this renamed file with an audio app such as QuickTime.
Sound 1. Webpage Digital Code (Boast 2020)
If this has all worked for you, and are listening now, what you are hearing is the webpage. This is not some cleaver trick, not some overdub. You are actually listening to the digital code that makes up the image of this web page. The digital code does not care if it is viewed (rendered in a browser), analyzed as data (as is done by Google of all its indexed webpages), or played as sound (as you are doing with this link). The digital does not refer to any one rendering, except by convention. We agree that a webpage is a webpage, and we choose to render it with a browser accordingly, but we don't have to.
Us Westerners, and I am referring to me and my colleagues from my European culture, have been obsessed for centuries with systematising knowledge. We reproduce our cultural traditions in our digital platforms. Databases, as I have tried to show, are not neutral technologies. Neither are they indisputable means of managing information. They are desires manifest – the cultural desires of Western Enlightenment traditions to systematise our knowledge, and everyone else’s.
Databases, especially relational databases, were developed fully accepting the ontologies of the museum, the archive and the encyclopaedia. The database arises from the same genealogies as museum documentation, and even exhibition.
The problems with online information systems, museum information systems in particular, the subject of this publication, are not that we simply have not figured out how to do information, digitally or otherwise. We are very good at informing, when we want to be.
The problem is that the museum sector is very bad at knowledge work, rarely moving beyond an empty trope of re-performing "show and tell." If the purpose of a museum is to collect and engage with diverse knowledges and knowledge communities, and making these diverse understandings available to the public, I am afraid that I have lost all faith in its ability to do so. I have not lost faith in individuals in museums, nor in individual museums, but I have come to think that the museum sector as a whole is institutionally impotent for this sort of work.
Exceptions do exist, as evidenced by the excellent work of the Info-Forum Museum Project, and the “Documenting and Sharing Information on Ethnological Materials: Working with Native American Tribes” project, led by Atsunori Ito, in particular. Projects such as Dr. Ito’s (https://ifm.minpaku.ac.jp/hopi/) are succeeding because he and his Hopi collaborators understand that what they are collecting are not representations, not authorised bits of data, but accounts, stories and dialogues about the Hopi knowledge world. They are using digital systems as media, to try and communicate a complex, diverse and changing knowledge of these objects, using digital systems to record and present dialogs, discussions, reminiscences, accounts of tradition and use, etc.
The point of all this toing and froing about digitality and databases has been, I hope, to drive home two points:
First, that when we want to work with digital technologies, and databases in particular, to achieve our collaborative ends, we must start by realising that there are built in consequences, affordances, that we must take into account. These are not neutral media, and the technologies have built-in assumptions about not only use and organisation, but, more importantly, about knowledge and knowing.
Second: That we can overcome these affordances, or at least make them dance to our own tunes, very easily. When choosing to work with digital media, we are not bound by any one set of organisations, representations, or expressive tropes. We have a level of expressive freedom that is unprecedented in any other medium. Certainly we must continue to do so by working in the technologies, in the media, but we can make our code dance in any number of ways we wish.
We can break with tradition, with the Western tradition of centralised, authorised and systematised knowledge. I believe that we can create a collaborative understanding of the objects held within anthropology museums – an understanding, or set of accounts, that are co-created by both the museum and the communities whose patrimony these objects are. However, we must first recognise that the systems we seek to apply are products of those very traditions we seek to break away from. The good news is that systems, including databases, are not fixed digital realities that we are forced to apply – they are programmed ways of working using a digital media which is fundamentally non-representational. Digitality is a medium within which we can achieve some of our desires, but we have to strip it down to the basics and build it up again, in new and appropriate ways.
Note
1) This is not completely true as Baudot’s code was modified somewhat by Donald Murray in 1901 to better accommodate a QWERTY keyboard. The code also underwent several minor modifications in the 20th century until being incorporated into the ASCII code in the early 1960s (Copland 2006:38).
References
- Bachman, C.
-
1962Integrated Data Store : The Information Processing Machine that we need. Report of presentation given at the General Electric Users Symposium, Kiamesha Lake, New York, on the 17th and 18th of May, 1962. Internal Document of GE.
- Boast, R.
-
2017The Machine in the Ghost: Digitality and its Consequences. London: Reaktion Books.
- Christen, K.
-
2006Ara Irititja: Protecting the Past, Accessing the Future: Indigenous Memories in a Digital Age. A Digital Archive Project of the Pitjantjatjara Council. Museum Anthropology 29(1): 56–60.
- Copeland, B. J. (ed.)
-
2006Colossus: The Secrets of Bletchley Park's Codebreaking Computers. Oxford: Oxford University Press.
- Grier, D. A.
-
2005When Computers were Human. Princeton: Princeton University Press.
- Ito, A. (supervised)
-
2018RECONNECTING Source Communities with Museum Collections. https://ifm.minpaku.ac.jp/hopi/ (Retrieved 29 January 2020)
- Kay, A.
-
1975Personal Computing. Paper presented at the meeting '20 Years of Computer-Science. Institute di Elaborazione della Informazione, Pisa, Italy. pp. 2-30.
- Lowe, A. and S. Schaffer (eds.)
-
2000N01se: Universal Language, Pattern Recognition, Data Synaesthetics. Cambridge: Kettles Yard.
- Neil-Binion, D.
-
2015The Reciprocal Research Network (RRN). Visual Resources 31(3): 1-5.
- Nelson, T.
-
1965File Structure for the Complex, the Changing, and the Indeterminate. Association for Computing Machinery: Proceedings of the 20th National Conference, pp. 84-100.
- NoSQL
-
2009(12 May 2009) http://blog.sym-link.com/posts/2009/12/nosql_2009/ (Retrieved 27 January, 2016)
- Redmond E. and J. Wilson
-
2012Seven Databases in Seven Weeks: A Guide to Modern Databases and the NoSQL Movement. Dallas: The Pragmatic Bookshelf.
- Redmond, K. C. and S. Thomas M.
-
1980Project Whirlwind: The History of a Pioneer Computer. Bedford, MA: Digital Press.
- Rowley, S.
-
2013The Reciprocal Research Network: The Development Process. Museum Anthropology Review 7(1-2): 22-43. (Available free from: https://scholarworks.iu.edu/journals/index.php/mar/article/view/2172/4562)
- Smith, B. C.
-
2000Brian Cantwell Smith. In A.Lowe and S. Schaffer (eds.) N01SE: Universal Language, Pattern Recognition, Data Synaesthetics. Cambridge: Kettles Yard.
- Srinivasan, R., J. Enote, K. M. Becvar, and R. Boast
-
2009Critical and Reflective Uses of New Media Technologies in Tribal Museums. Museum Management and Curatorship 24(2): 161-181.
- Strauch, C.
-
2011NoSQL Databases. Stuttgart: Stuttgart Media University. (Available free from: http://www.christof-strauch.de/nosqldbs.pdf)
- Takahashi, M. and S. Azuma
-
2009The Manga Guide to Databases. San Francisco: No Starch Press.
- Weltevrede, E.
-
2016Repurposing Digital Methods: The Research Affordances of Platforms and Engines. Ph.D. Dissertation, University of Amsterdam, Amsterdam.
Sound
- Boast, R.
-
2020Webpage Digital Code. 01:11.
https://vimeo.com/396813914/29bb8d9de2. (Retrieved March 11, 2020)